Navegue por las siguientes preguntas para conocer más sobre Loterre.
Loterre (acrónimo de Linked open terminology resources) es una plataforma para exponer y compartir terminología científica multidisciplinaria y multilingüe.
Basado en un triplestore, cumple con los estándares web de datos abiertos y vinculados (LOD) y los principios de FAIR, cuyo objetivo es hacer que los datos sean fáciles de encontrar, accesibles, interoperables y reutilizables.
Las terminologías disponibles en Loterre pueden satisfacer las necesidades de búsqueda de texto, anotación semántica, búsqueda de información o traducción.
El acceso a los recursos de Loterre está abierto a todos; Su reutilización depende de su licencia.
Loterre ofrece acceso a recursos terminológicos científicos, le permite:
consultar
buscar a través de un motor de búsqueda, una interfaz SPARQL y una API
descargar en diferentes formatos
Loterre también ofrece servicios en línea, cuyo contenido se detalla en el apartado «Servicios de Loterre» de esta página.
Los productores de recursos terminológicos que deseen publicarlos en la plataforma Loterre están invitados a consultar la Carta Loterre y a solicitarla a través del formulario de contacto.
Los principios FAIR (Findability, Accessibility, Interoperability, Reusability) aplicables a los datos científicos fueron desarrollados por Force11 y publicados por Wilkinson et al. en 2016 (The FAIR Guiding Principles for scientific data management and stewardship). Los pasos de la FAIRification han sido explicados por GO FAIR.
Estos principios constituyen una guía de buenas prácticas para la gestión y reutilización de datos y metadatos tanto por parte de las máquinas como de los seres humanos. Sin embargo, no constituyen una especificación porque no recomiendan ningún estándar, tecnología o formato de datos en particular.
Los (meta)datos terminológicos presentes en Loterre cumplen con todos los principios de FAIR. También pueden participar en la FAIRización de (meta)datos de investigación promoviendo su interoperabilidad semántica (a través de conceptos de vocabulario o tesauro).
De hecho, estos datos son:
Fáciles de encontrar: concepto asociado a un identificador único y persistente (URI)
Accesibles: protocolo de acceso libre y abierto (http)
Interoperables: lenguaje para compartir y representar el conocimiento (SKOS)
Reutilizables: claro acuerdo de licencia (CC o Etalab)
Del mismo modo, los servicios de Control, Transformación y Mapeo tienen como objetivo facilitar la creación y lo enriquecimiento de terminologías en formato SKOS/RDF-XML, de acuerdo con los principios FAIR.
Loterre pretende cumplir con los principios del LOD (Linked Open Data) presentados en 2006 por el W3C (Tim Berners-Lee): los recursos terminológicos se consideran aquí como conjuntos organizados de términos (conceptos de designación) que son conjuntos de datos de libre acceso a través de tecnologías de web semántica.
Linked Data o «web de datos enlazados» se basa en 4 reglas básicas:
Identificar cada recurso (o concepto) mediante un URI (Uniform Resource Identifier)
Usar URIs HTTP (dereferibles) para acceder a la información sobre estos recursos
Al descodificar una URI, volver a los datos estructurados utilizando la familia de estándares W3C: modelo (trillizos RDF) y lenguajes (SKOS, RDFS, OWL,…) para describirlos; SPARQL para consultarlos
Vincular conceptos (datos RDF) pertenecientes a diferentes vocabularios o terminologías a través de alineaciones a través de sus URIs, con el fin de crear una red de enlaces RDF y así descubrir nuevas relaciones
Al añadir licencias abiertas para la distribución y reutilización de los recursos publicados en la web, Loterre cumple con las reglas de «Linked Open Data».
T. Berners-Lee también propuso una clasificación progresiva de los LOD con 5 estrellas de acuerdo con los siguientes criterios:
* Datos disponibles gratuitamente en la web, con mención de una licencia abierta
** Datos en un formato estructurado y legible por la máquina
*** Formatos no patentados (CSV, JSON…)
**** Estándares abiertos del W3C (RDF, XML, SPARQL) y URI como identificador de recursos
***** Datos vinculados a otros datos del RDF a través de alineaciones en el LOD Cloud
Por último, los recursos integrados en el triplestore están destinados, en la medida de lo posible, a cumplir con las mejores prácticas del W3C para la publicación de datos relacionados (W3C, 2014).
Todos los recursos expuestos en Loterre son compatibles con estas normas y principios y pueden clasificarse como 4 o 5 estrellas:
Licencia libre (lo) y/o abierta (CC BY)
Formatos estándar: SKOS, XML, JSON-LD, CSV
URIs alineables
Para citar un recurso de Loterre, indique «Loterre», luego el título largo del recurso seguido de su DOI. Por ejemplo, «Loterre, Tesauro de la ciencia abierta, https://dx.doi.org/10.13143/lotr.9297».
Si no hay DOI, reemplácelo con el URI del recurso; por ejemplo, «Loterre, Vocabulario temático de geografía, http://data.loterre.fr/vocabs/BGI/GT».
Servicios de Loterre
Además de descargar terminologías alojadas, Loterre ofrece servicios para cualquier productor de terminología, ya sea que quieran exponer o no sus recursos en Loterre.
Los servicios Controlar, Transformar y Mapear tienen como objetivo facilitar la creación y el enriquecimiento de terminologías en formato SKOS / RDF-XML de acuerdo con los principios FAIR (fácil de encontrar, accesible, interoperable, reutilizable).
n.b.: Los datos de usuario procesados por estos servicios no son almacenados por el Inist-CNRS.
Este servicio permite mapear un archivo SKOS/RDF-XML válido con un recurso de terminología de Loterre de destino especificado por el usuario. Si un término (término preferido o sinónimo) de un concepto A del vocabulario de origen se encuentra en un concepto B del vocabulario de destino (con la misma etiqueta de lengua), una propiedad «skos:exactMatch» es insertado en el concepto A con el URI del concepto de destino en el atributo «rdf:resource».
Procesa archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Notar que el mapeo se basa en una comparación de cadenas de caracteres que deben ser idénticas en ambos lados sin tener en cuenta el contexto; los mapeos deberán ser validadas por el usuario.
En Loterre se proponen 2 variantes de este servicio:
«Mapear un archivo SKOS/RDF-XML válido con un vocabulario de Loterre insertando la propiedad ‘skos:exactMatch’ en el archivo fuente»:
si un término (término preferido o sinónimo) de un concepto A del vocabulario de origen se encuentra en un concepto B del vocabulario de destino (con la misma etiqueta de lengua), una propiedad «skos:exactMatch» es insertado en el concepto A con el URI del concepto de destino en el atributo «rdf:resource».
«Mapear un archivo SKOS/RDF-XML válido con un vocabulario de Loterre produciendo un archivo de mapear»:
si un término (término preferido o sinónimo) de un concepto A del vocabulario de origen se encuentra en un concepto B del vocabulario de destino (con la misma etiqueta de lengua), se crea un nuevo archivo (formato RDF-XML) y para cada mapeo:
se crea un registro «rdf:Description»,
el URI del concepto fuente se coloca en el atributo «rdf:about» de este registro,
una propiedad «skos:exactMatch» se crea en este registro,
el URI del concepto de destino se coloca en el atributo «rdf:resource» de esta propiedad.
Los datos en el archivo de mapeo pueden ser añadidos tal cual al principio o al final del archivo fuente.
El servicio «Anotar» permite buscar, en una porción de texto escrito en francés, inglés o español, la presencia de términos (etiquetas preferidas y sinónimos) de una terminología alojada en Loterre.
Muestra el texto en el que se han destacado los términos detectados y una tabla de los términos y conceptos correspondientes, con su URI.
El servicio «Controlar» permite controlar en línea la validez de un archivo de terminología guardado en formato SKOS.
Se ofrecen tres clases de verificaciones: validez de colección, validez de concepto y validez de esquema de concepto.
Validez de las colecciones
El servicio «Controlando un archivo SKOS/RDF-XML en el nivel de colección» pocesa los archivos que contienen «skos:Collection» o «isothes:ConceptGroup» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]]» o «rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]]».
Se realiza un análisis preliminar del recurso para determinar:
el número de bloques «Collection»;
el nombre y número de elementos (propiedades) que componen los bloques «Collection».
A continuación, realiza las comprobaciones y devuelve los resultados en forma de una tabla que detalla los tipos de anomalías detectadas.
Lista de controles realizados:
Código
Descripción de la anomalía
Col-0
El recurso no contiene el elemento skos:Collection ni el elemento rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]] ni elemento «rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]]».
Col-@0
Identificador ausente. El elemento colección no tiene un identificador.
Col-@N
Atributo no autorizado. Solo el atributo «rdf:about» está autorizado por el elemento «skos:Collection» o rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]] o «rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]]».
Col-2
Anomalía de estructuración de colecciones. A pesar de la presencia de una «isothes:superGroup» propiedad en las colecciones, no se encontró ninguna «isothes:subGroup» propiedad en la súper colección correspondiente. Puede usar el menú «Insertar colecciones más estrechas en un archivo SKOS/RDF-XML válido» para solucionar el problema.
Col-3
Inconsistencia a nivel del identificador del recurso (URI). El valor del atributo rdf:resource en el elemento skos:inScheme de la colección es diferente del identificador del recurso (ConceptScheme).
Col-4
Miembro inexistente. Una miembro no es un concepto de este recurso. Cree el concepto correspondiente o elimine este miembro.
Col-5
El identificador contiene un carácter no autorizado (espacio, apóstrofo, comillas, corchete izquierdo, corchete derecho).
Validez de los conceptos
El servicio «Controlando un archivo SKOS/RDF-XML a nivel de concepto» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Se realiza un análisis preliminar del recurso para determinar:
el número de bloques «skos:ConceptScheme», «skos:Concept», «skos:Collection» y «skosxl:Label»;
el nombre y número de elementos (propiedades) que componen los bloques;
los lenguas del recurso.
A continuación, realiza las comprobaciones y devuelve los resultados en forma de una tabla que detalla los tipos de anomalías detectadas.
Lista de controles realizados:
Código
Descripción de la anomalía
D-Id
Unicidad del identificador (URI) de un concepto dado. Dos conceptos diferentes no pueden tener el mismo identificador.
E-0
Presencia de un elemento vacío (propiedad vacía). Puede interferir con la continuación del programa de control. También puede evitar l’importación en algunos editores de terminología.
@-0
Presencia de un atributo vacío.
R-A1
Conflicto entre relaciones semánticas: el mismo concepto es un concepto relacionado y un concepto más amplio del concepto actual.
R-FX1
Relación jerárquica reflexiva: un concepto es su propio concepto más amplio.
R-FX2
Relación asociativa reflexiva: un concepto es su propio concepto relacionado.
R-31
Conflicto entre relaciones asociativas y jerárquicas: si el concepto A tiene el concepto B como un concepto más específico y el concepto C como un concepto relacionado, entonces C no puede ser un concepto más específico de B porque el concepto C no puede vincularse simultáneamente con el concepto A por dos relaciones disjuntas «skos:narrowerTransitive» y «skos:related». Ver detalles en SKOS-Primer.
R-32
Conflicto entre relaciones asociativas y jerárquicas: si el concepto A tiene el concepto B como un concepto más amplio y el concepto C como un concepto relacionado, entonces C no puede ser un concepto más amplio de B porque el concepto C no puede vincularse simultáneamente con el concepto A por dos relaciones disjuntas «skos:broaderTransitive» y «skos:related». Ver detalles en SKOS-Primer.
R-B3
Conflicto entre relaciones semánticas: el mismo concepto es un concepto más específico y un concepto más amplio del concepto actual.
R-A2
Choque entre relaciones semánticas: el mismo concepto es un concepto más específico y un concepto relacionado del concepto actual.
R-NS
Relación asociativa (skos:related) no simétrica.
R-0
Relación (skos:related, skos:broader or skos:narrower) que se dirige a un concepto inexistente.
R-OR
Concepto huérfano: un concepto que no es un concepto cabecera, y que no tiene un concepto genérico ni un concepto específico.
CS-0
Concepto no vinculado al esquema de conceptos a través del elemento «skos: inScheme».
CS-3
Inconsistencia a nivel del identificador de recurso (URI). El valor del atributo «rdf: resource» en el elemento «skos: inScheme» es diferente del identificador de recurso.
LP-0
Etiqueta léxica preferente ausente para una de las lenguas del recurso.
LP-N1
Más de una etiqueta léxica preferente por lengua.
LP-LA1
Etiqueta léxica preferente / etiqueta léxica alternativa duplicada dentro del mismo concepto.
LP-LC1
Etiqueta léxica preferente / etiqueta léxica oculta duplicada dentro del mismo concepto.
LP-LP2
Misma etiqueta léxica preferente para dos conceptos diferentes.
LP-LA2
Etiqueta léxica preferente / etiqueta léxica alternativa duplicada entre dos conceptos diferentes.
LP-LC2
Etiqueta léxica preferente / etiqueta léxica oculta duplicada entre dos conceptos diferentes.
LA-LA1
Etiqueta léxica alternativa duplicada dentro del mismo concepto.
LA-LA2
Misma etiqueta léxica alternativa para dos conceptos diferentes.
LA-LC1
Etiqueta léxica alternativa / etiqueta léxica oculta duplicada dentro del mismo concepto.
LA-LC2
Etiqueta léxica alternativa / etiqueta léxica oculta duplicada entre dos conceptos diferentes.
LC-LC1
Etiqueta léxica oculta duplicada dentro del mismo concepto.
LC-LC2
Misma etiqueta léxica oculta para dos conceptos diferentes.
Validez de esquema de conceptos
El servicio «Controlando un archivo SKOS/RDF-XML a nivel de esquema de conceptos» procesa los archivos que contienen «skos:ConceptScheme» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#ConceptScheme’]]» son procesados por este servicio.
Se realiza un análisis preliminar del recurso para determinar:
el número de bloques «ConceptScheme»;
el nombre y número de elementos (propiedades) que componen los bloques «ConceptScheme».
A continuación, realiza las comprobaciones y devuelve los resultados en forma de una tabla que detalla los tipos de anomalías detectadas.
Lista de controles realizados:
Código
Descripción de la anomalía
CS-N
Elemento ConceptScheme no presente. Archivo no contiene el elemento skos:ConceptScheme ni el elemento rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#ConceptScheme’]]. Use el menú «Insertar un elemento ConceptScheme» para resolver el problema.
CS-0
Esquema de conceptos sin identificador (URI).
CS-1
Atributo no autorizado por el elemento skos:ConceptScheme. Solo se permite el atributo rdf:about.
CS-2
Esquema de conceptos sin propiedad skos:hasTopConcept. A pesar de una fuerte estructuración, el elemento skos:ConceptScheme no contiene las propiedades skos:hasTopConcept para enumerar los conceptos cabecera. Use el menú «Inserte las propiedades hasTopConcept en un archivo SKOS» para resolver el problema.
CS-3
Inconsistencia a nivel del identificador del recurso (URI). El valor del atributo rdf:resource en el elemento skos:inScheme de un concepto dado es diferente del identificador del recurso.
El servicio «Transformar» permite generar terminología en formato SKOS-XML a partir de un archivo CSV, corregir anomalías en un archivo SKOS-XML o convertir terminología inicialmente en formato SKOS-XML a otros formatos.
Las operaciones que ofrece este servicio se pueden agrupar en tres tipos: corrección, enriquecimiento y conversión.
Corrección
Estos módulos tienen por objeto, en particular, corregir las anomalías detectadas previamente por el servicio « Controlar »
Eliminar duplicados en los términos
El servicio «Eliminar duplicados en los términos de un archivo SKOS/RDF-XML» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]»
A nivel de cada concepto, este servicio funciona de la siguiente manera:
Se conservan todas las etiquetas léxicas preferentes siempre que solo haya una por idioma:
Si para un mismo idioma existen dos terminos preferidos idénticos, solo se conserva uno.
Si, para el mismo idioma, existen dos terminos preferidos diferentes, se conserva la primera y la otra se coloca en «skos:altLabel».
Las etiquetas léxicas alternativas se comparan entre sí y con la etiqueta léxica preferente de la misma lengua:
si el mismo término aparece varias veces como una etiqueta léxica alternativa de la misma lingua, solo se mantiene una aparición;
si el mismo término aparece como una etiqueta léxica alternativa y la etiqueta léxica preferente de la misma lengua, solo se conserva la etiqueta léxica preferente.
Las etiquetas léxicas ocultas se comparan entre sí, con la etiqueta léxica preferente y con las etiquetas léxicas alternativas de la misma lengua:
si el mismo término aparece varias veces como una etiqueta léxica oculta de la misma lengua, solo se mantiene una aparición;
si el mismo término aparece como una etiqueta léxica oculta y la etiqueta léxica preferente de la misma lengua, solo se conserva la etiqueta léxica preferente;
si el mismo término aparece como una etiqueta léxica oculta y la etiqueta léxica alternativa de la misma lengua, solo se conserva la etiqueta léxica alternativa.
Al final de este proceso, verifique el archivo nuevamente utilizando el servicio Controlando un archivo SKOS/RDF-XML a nivel de concepto para asegurarse de que no haya más duplicados.
Corrección de anomalías de simetría de conceptos asociados
Si un concepto A está asociado a un concepto B a través de la propiedad skos:related, el concepto B debe estar asociado con el concepto A porque la relación es simétrica. Si no se marca esta condición, este servicio permite insertar la propiedad skos:related que falta.
El servicio «Corregir anomalías de simetría de conceptos relacionados en un archivo SKOS/RDF-XML» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Si no se marca la condición de simetría definida anteriormente, este servicio permite insertar la propiedad «skos:related» que falta.
Nota que este tratamiento no se aplica a ninguna de las subpropiedades de la propiedad «skos:related».
Inserción de conceptos específicos
La relación jerárquica entre un concepto A y un concepto B se expresa utilizando la propiedad «skos:broader» y la presencia a nivel de concepto de una relación «skos:narrower» (que es la relación inversa) no es obligatorio porque se infiere de la relación «skos:broader».
Sin embargo, el buen funcionamiento de algunas aplicaciones (como SKOSMOS) requiere la presencia de ambas relaciones.
El servicio «Insertar conceptos específicos en un archivo SKOS/RDF-XML válido» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Este servicio hace posible insertar en el concepto genérico tantas propiedades «skos:narrower» como conceptos específicos de este concepto.
Inserción de colecciones específicas
La relación jerárquica entre una colección A y una colección B se expresa utilizando la propiedad «isothes:superGroup». La presencia de una propiedad «isothes:subGroup» (que es la relación inversa) en el nivel de la colección B no es obligatoria porque se infiere de «isothes:superGroup» propiedad.
Sin embargo, el buen funcionamiento de algunas aplicaciones (como SKOSMOS) requiere la presencia de ambas relaciones.
El servicio «Insertar colecciones más estrechas en un archivo SKOS/RDF-XML válido» procesa los archivos que contienen «skos:Collection» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]]» o «rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]]».
Este servicio hace posible insertar en el nivel de la colección más amplia tantas propiedades «isothes:subGroup» como colecciones más estrechas de esta colección.
Enriquecimiento
Insertar un bloque ‘ConceptScheme’ y una licencia
El servicio «Insertar un bloque ‘ConceptScheme’ en un archivo SKOS/RDF-XML» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Este servicio inserta dos bloques al comienzo de un archivo SKOS/RDF-XML:
– Un bloque «cc: License» con la licencia predeterminada Creative Commons CC-BY 4.0 que debería cambiarse si el recurso se libera bajo una licencia diferente.
– Un bloque «skos:ConceptScheme» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#ConceptScheme’]]» con:
un URI derivado de los identificadores de los conceptos ;
propiedades para metadatos ; para ser completado / modificado por el usuario en el nivel del archivo de salida:
títulos del recurso en español, inglés y francés (dc:title),
descripciones del recurso en español, inglés y francés (dc:description),
sujetos del recurso en español, inglés y francés (dc:subject),
nombre del creador (dc:creator),
nombre de la licencia (cc:license),
nombres del recurso en español, inglés y francés de la organización a la que se asignará el recurso (cc:attributionName),
sitio web de la organización / institución (cc:attributionURL),
conceptos cabecera (skos:hasTopConept) si el recurso está altamente estructurado,
lenguas del recurso calculados a partir de los códigos de lengua utilizados para las etiquetas preferente de los conceptos (dcterms:language con lexvo / códigos ISO 639-3),
fecha de creación (dcterms:created),
fecha de modificación (dcterms:modified),
versión del recurso (owl:versionInfo).
Después de generar los campos, su contenido textual debe ser completado y validado por el usuario.
Insertar las propiedades «hasTopConcept»
El servicio «Inserte las propiedades «hasTopConcept» en un archivo SKOS/RDF-XML válido» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Este servicio inserta una propiedad «skos:hasTopConcept» en el bloque «ConceptScheme» para cada concepto que no tiene una propiedad «skos:broader».
No utilice este servicio para recursos no estructurados o poco estructurados.
Insertar las propiedades «topConceptOf»
El servicio «Inserte las propiedades «topConceptOf» en un archivo SKOS/RDF-XML válido» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Este servicio inserta una propiedad «skos:topConceptOf» en cada concepto que no tiene una propiedad «skos:broader».
No utilice este servicio para recursos no estructurados o poco estructurados.
Asignar identificadores ARK
El servicio «Asignar identificadores ARK a un archivo SKOS/RDF-XML válido» procesa los archivos que contienen «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]».
Este servicio permite la sustitución de los identificadores (URI) de un archivo SKOS/RDF-XML por identificadores ARK creados de acuerdo con las recomendaciones de California Digital Library (CDL).
Un identificador ARK tiene la siguiente sintaxis:
La NMA (Name Adressing Authority ; Anfitrión de Autoridad de Mapeo de nombres), su función es hacer que se pueda hacer clic en el URL en un navegador web.
El identificador ARK real que consiste en:
la etiqueta «ark:/»,
el identificador NAAN (Name Assigning Authority Number; número de autoridad asignante del nombre) que se atribuye bajo demanda por la CDL.
La transformación se realiza en dos etapas:
1- Reemplazar el URI del recurso (a nivel del esquema de conceptos) por el siguiente URI genérico: http://mi_sitio.es/ark:/NAAN/ABC. El viejo URI se pone en una etiqueta «dc:identifier».
A nivel de concepto, una secuencia alfanumérica de 8 caracteres seguida de un guión y luego una suma de verificación (check sum) completa este prefijo y constituye un identificador ARK único para cada concepto del recurso.
cada una de las relaciones «skos:broader», «skos:narrower», «skos:related»,
las posibles propiedades «skosxl:prefLabel», «skosxl:altLabel», «skosxl:hiddenLabel»,
los miembros de las posibles colecciones,
los posibles elementos «skosxl:Label».
Para tener identificadores ARK que cumplan con las recomendaciones de CDL (ver detalles aquí), el URI genérico debe reemplazarse de la siguiente manera:
Reemplace la parte «http://mi_sitio.es» (autoridad de mapeo) por el bueno URL,
Mantener la etiqueta «/ark:/»,
Reemplace «NAAN» (número de autoridad asignante del nombre) con el NAAN de la organización,
Reemplace «ABC» con un código alfanumérico corto correspondiente al recurso en sí.
Aquí hay un ejemplo real: http://data.loterre.fr/ark:/67375/1WB
Tenga en cuenta que, en ausencia de NAAN, el URI no puede considerarse como un ARK URI, pero puede usarse sin la parte «ark:/ NAAN/»; la última parte es un identificador único.
Conversión
Loterre ofrece diferentes módulos de conversión.
Transformar un archivo CSV en un archivo SKOS-XML
Este servicio hace posible generar un archivo SKOS-XML a partir de una hoja de cálculo (Excel, OpenOffice, etc.) guardada en CSV.
Loterre ofrece dos variantes de este servicio, dependiendo de si el separador de campos en el archivo CSV es un punto y coma o una coma :
Transforme un archivo CSV separado por punto y coma en un archivo SKOS-XML
Transforme un archivo CSV separado por comas en un archivo SKOS-XML
n.b.: en el caso de un archivo CSV cuyo separador es un punto y coma, usar los comillas dobles (» / quote) como delimitador de texto para los campos que pueden contener el punto y coma para la puntuación, y ponga las comillas al principio y al final del texto para que el punto y coma no se considera como un separador de campo, y si el texto en sí contiene comillas, debe duplicarse.
El archivo debe :
usar este separador «§§» para campos de múltiples valores (ejemplo: hormona§§medicamento),
usar los nombres de las etiquetas de la siguiente tabla:
Datos terminológicos
Etiqueta a utilizar
xx = código ISO de lengua (*)
Comentario
Etiquetas léxicas preferentes
prefLabel_xx
Se espera una etiqueta «prefLabel_es»
Etiquetas léxicas alternativas
altLabel_xx
Etiquetas léxicas ocultas
hiddenLabel_xx
Definición
definition_xx
Nota
note_xx
Nota de alcance
scopeNote_xx
Nota editorial
editorialNote_xx
Nota histórica
historyNote_xx
Nota de cambio
changeNote_xx
Ejemplo
example_xx
Concepto más amplio
broader_xx
Se espera una etiqueta «broader_es»
Concepto asociado
related_xx
Se espera una etiqueta «related_es»
Colección
group_xx
Se espera una etiqueta «group_es»
Mapeo exacto
exactMatch
Mapeo cercano
closeMatch
Mapeo amplio
broadMatch
Mapeo estrecho
narrowMatch
Mapeo relacionado
relatedMatch
(*) Reemplace «xx» con el código ISO de 2 caracteres del idioma; ejemplo «prefLabel_es» para la etiqueta léxica preferente española. Ver la lista de códigos ISO 639-1.
Los datos se transforman de la siguiente manera:
Se crea un archivo RDF-XML para contener todo el recurso terminologíco.
Cada línea, excepto la primera, se convierte en «skos:Concept», si hay un identificador presente, se le atribuye al concepto; de lo contrario, se le asigna un URI temporal en el atributo «rdf:about»
Las etiquetas en la primera línea se convierten a su contraparte de SKOS, por ejemplo, prefLabel_es se convierte en «skos:prefLabel» con un atributo «xml:lang = ‘es'».
El contenido de cada celda se coloca en la propiedad SKOS apropiada. Si el contenido tiene varios valores, se divide en tantas propiedades como valores separados por el separador «§§».
Las relaciones relacionadas y más amplias se procesan en dos etapas: en primer lugar, se genera una propiedad «skos:related» o «skos:broader» para cada término relacionado o más amplio luego, en un segundo paso, es el URI del concepto correspondiente a los términos en cuestión que se pone en el atributo «rdf:resource».
Si el archivo tiene grupos, se creará «skos:Collection» para cada grupo. Asegúrate de traducir los grupos al menos al inglés.
Además, la transformación también inserta dos bloques al principio del archivo RDF-XML:
– Un bloque «cc:License» con la licencia Creative Commons CC-BY 4.0 predeterminada que se debe cambiar si el recurso se libera bajo una licencia diferente.
– Un bloque «skos:ConceptScheme» con:
un URI derivado de los identificadores de los conceptos ;
propiedades para metadatos ; para ser completado / modificado por el usuario en el nivel del archivo de salida:
títulos del recurso en español, inglés y francés (dc:title),
descripciones del recurso en español, inglés y francés (dc:description),
sujetos del recurso en español, inglés y francés (dc:subject),
nombre del creador (dc:creator),
nombre de la licencia (cc:license),
nombres del recurso en español, inglés y francés de la organización a la que se asignará el recurso (cc:attributionName),
sitio web de la organización / institución (cc:attributionURL),
conceptos cabecera (skos:hasTopConcept) si el recurso está altamente estructurado,
lenguas del recurso calculados a partir de los códigos de lengua utilizados para las etiquetas preferente de los conceptos (dcterms:language con lexvo / códigos ISO 639-3),
fecha de creación (dcterms:created),
fecha de modificación (dcterms:modified),
versión del recurso (owl:versionInfo).
El contenido textual de estos campos debe ser completado y validado por el usuario.
Si los conceptos no tienen identificadores, el URI predeterminado del recurso es «http://www.mi_sitio.es/vocabs/ABC». También es la raíz del URI de conceptos, relaciones y posibles colecciones. Debe ser reemplazado de la siguiente manera:
Sustituir «http://www.mi_sitio.es/» par el URL correcto
Mantener «/vocabs/»
Sustituir «ABC» par un código alfanumérico corto correspondiente al recurso
En el nivel de concepto, el URI es una concatenación del URI del recurso con un identificador único; en el nivel de colección, el URI es una concatenación del URI del recurso con el nombre del grupo reemplazando los espacios con «_».
Para cambiar a los identificadores ARK, use la transformación «Asignar identificadores ARK a un archivo SKOS/RDF-XML válido».
Transformar un archivo SKOS/RDF-XML válido a un archivo CSV
Este servicio genera un archivo CSV a partir de un archivo SKOS/RDF-XML válido que contiene «skos:Concept» o «rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]]»
Loterre propone dos variantes, según la naturaleza del separador de campos deseado en el fichero CSV resultante:
Transformar un archivo SKOS/RDF-XML válido a un archivo CSV cuyo separador sea el punto y coma
Transformar un archivo SKOS/RDF-XML válido a un archivo CSV cuyo separador sea la coma
El archivo del producto se puede importar a un programa de hoja de cálculo (Excel, LibreOffice, etc.) para editarlo (consulte el procedimiento de importación en Excel más adelante).
Los datos se transforman de la siguiente manera:
Se crea un «encabezado de columna» de la primera fila a partir de los elementos (skos u otras propiedades) utilizados para describir los diferentes conceptos del archivo RDF-XML:
Se crea una etiqueta «ID» para los identificadores de los conceptos.
Las propiedades con un atributo «xml:lang» se enumeran tocando el nombre del elemento (sin espacio de nombres) con el código de lengua (por ejemplo, «skos:prefLabel/@ xml:lang=’es'»da la etiqueta «prefLabel_es»).
Para propiedades que tienen un atributo diferente a «xml:lang»:
los correspondientes a las relaciones semánticas («skos:broader», «skos:narrower» y «skos:related») se traducen en «broader_es», «narrower_es» y «related_es»,
los otros (propiedades de mapeo, etc.) se generan solo con el nombre del elemento (sin espacio de nombres, por ejemplo, «exactMatch» para «skos:exactMatch»).
Las propiedades que no tienen atributos se generan solo con el nombre del elemento (sin espacio de nombres).
Si el archivo contiene colecciones, se crea una etiqueta «group_es». Esta etiqueta puede ser redundante si los conceptos contienen propiedades que reflejan su pertenencia a grupos (dominio, microtesauro, etc.).
Luego, se genera una línea para cada concepto del archivo:
el contenido del atributo «rdf:about» se coloca en la columna «ID»,
el contenido de los elementos textuales (términos, definiciones, notas, etc.) se paga en la columna correspondiente al elemento y el código de lengua de este elemento.
las relaciones jerárquicas y asociativas (enlaces) se traducen reemplazándolas por los términos preferenciales españoles correspondientes,
el contenido de los otros elementos está fuera como está,
si el concepto pertenece a una colección, el nombre español de la colección se coloca en la columna «group_es».
Notar que:
los contenidos de los diferentes campos se colocan entre comillas para evitar los problemas de separación cuando estos contenidos contienen el punto y coma como elemento de puntuación,
si el contenido de un campo contiene comillas, las comillas se duplican para protegerlas,
los contenidos de los campos de ocurrencia múltiple (por ejemplo, «skos:altLabel») se colocan en la misma «celda» pero separados por este separador «§§».
Para importar el archivo a Excel:
Crear un nuevo archivo en Excel («Archivo» / «Nuevo»).
Haga clic en el menú «Datos», elija «[Obtener datos externos]/»Desde un archivo de texto» y luego elija el archivo para importar con el explorador de archivos.
Importar el archivo (botón «Importar»).
En el «Asistente para importar texto
marque la casilla «Delimitados»,
en el menú desplegable «Origen del archivo», elija «65001: Unicode (UTF-8)»,
marque la casilla «Mis datos tienen encabezados».
Haga clic en «Siguiente»:
En la columna «Separadores», marque la casilla «Punto y coma»,
Mantenga las comillas («) en el nivel del menú «Calificador de texto «,
Verifique el renderizado en la «Vista previa de los datos»,
Haga clic en «Finalizar».
El archivo modificado en Excel y guardado en CSV se puede transformar en SKOS utilizando el servicio «Transforme un archivo CSV separado por punto y coma en un archivo SKOS-XML» o «Transforme un archivo CSV separado por comas en un archivo SKOS-XML» de acuerdo con el separador de campo aplicado en el momento del registro.
Transformar un archivo SKOS/RDF-XML a HTML
Este servicio permite generar un archivo HTML a partir de un archivo SKOS válido. Procesa los archivos que contienen «skos:Concepto» o «rdf:Descripción» de tipo «Concepto».
Loterre propone dos variantes, según la versión lingüística elegida:
Convertir un archivo SKOS/RDF-XML válido en un archivo html – Versión francesa
Convertir un archivo SKOS/RDF-XML válido en un archivo html – versión en inglés
Las entradas de terminología se presentan en el orden alfabético de preferencia (francés o inglés):
términos (preferidos y sinónimos) en el idioma elegido
definiciones y notas en el idioma elegido
relaciones (términos genéricos, asociados y específicos)
términos preferidos en otros idiomas
posibles grupos de afiliación
alineaciones
cualquier referencia bibliográfica
la(s) fuente(s) del concepto
La riqueza de la información mostrada dependerá del contenido y de la estructuración del archivo SKOS original.
Transformar un archivo SKOS/RDF-XML a PDF
Esta transformación genera un archivo PDF a partir de un archivo SKOS válido.
Loterre propone dos variantes, según la versión lingüística elegida para el recurso:
Transformar un archivo SKOS/RDF-XML en un archivo PDF correspondiente a la versión francesa del recurso.
Transformar un archivo SKOS/RDF-XML en un archivo PDF correspondiente a la versión en inglés del recurso.
Se generan varias secciones basadas en el contenido y la estructura del :
Índice alfabético.
Entradas de terminología detallada (en inglés o francés) con :
términos, definiciones, notas
relaciones (términos genéricos, asociados y específicos)
condiciones preferentes en otros idiomas
posibles grupos de miembros
alineaciones
cualquier referencia bibliográfica
la(s) fuente(s) del concepto
La lista de entradas con :
la preferencia francesa
la preferencia inglesa
la página
La estructura de árbol si el recurso está estructurado.
Colecciones si el recurso contiene grupos.
Se insertan páginas adicionales:
una simple portada con el título del recurso (francés o inglés)
portada con :
título (francés o inglés) del recurso
versión
fecha de la última actualización
descripción (francés o inglés)
leyenda para entradas detalladas
licencia CC-BY 4.0 más logo
Contraportada:
título (francés o inglés) del recurso
descripción (francés o inglés)
licencia CC-BY 4.0 más logo
Tenga en cuenta que las portadas se pueden sustituir editando el archivo final con un editor de PDF.
El servicio «Descargar» permite descargarse todo el contenido de uno de los recursos almacenados en el triplestore de Loterre, en formato PDF, CSV, SKOS/XML o JSON-LD.
Lotterre Explorer utiliza la herramienta de código abierto LODEX para presentar una vista analítica de los recursos terminológicos expuestos en Lotterre. También permite explorar y ordenar la terminología de Loterre por dominios, idiomas, licencias, productores…, haciendo clic en los iconos de “Buscar” o “Gráficos”.
Como complemento a la búsqueda terminológica en Loterre, "Vocabs Explorer" ofrece una selección de recursos accesibles en línea: almacenes o directorios de terminología, vocabularios controlados, glosarios, léxicos, diccionarios, ontologías, tesauros, etc.
Gracias al uso de la herramienta de código abierto LODEX, esta selección se puede explorar y ordenar por tipos de contenido, campos científicos, temas, idiomas, productores..., haciendo clic en los iconos "Investigación" o "Gráficos".
Terminologías de Loterre
Las terminologías propuestas por terceros son objeto de un examen basado en criterios de calidad y formato. Los propietarios del sitio de Loterre se reservan el derecho de operar una moderación de las propuestas recibidas. Podrán negarse a integrar una terminología si consideran que no cumple los criterios que rigen la plataforma.
La cobertura científica de los datos expuestos en Loterre es multidisciplinar y pertenece a uno o varios de los campos científicos siguientes:
Ciencias y tecnologías
Matemáticas
Algebra
Análisis matemático
Análisis numérico, calculo científico
Combinatorio, estructuras ordenadas
Geometría
Matemáticas generales
Probabilidades y estadísticas
Sistemas dinámicos, análisis global et análisis sobre variedades
Teoría de los grupos
Topología, variedades y complejos celulares
Física
Acústica
Cristalografía
Electromagnetismo, óptica
Mecánica de los sólidos, mecánica de los fluidos, reología
Metrología
Física atómica y molecular
Física del estado condensado
Física de los gases y de los plasmas
Física nuclear
Física teórica, física cuántica, física estadística, relatividad y gravitación
Termodinámica, transferencias de calor
Ciencias de la Tierra y del universo
Aeronomía, meteorología, climatología
Astronomía
Geología, geofísica interna
Glaciología
Oceanografía
Química
Química analítica
Química general, química teórica y química física
Química mineral (inorgánica)
Química orgánica
Ciencias del ingeniero
Aeronáutica, transportes
Automática, búsqueda operacional
Electrónica, informática
Energía, electrotécnica, electro-energética
Ingeniería química, industrias químicas y para-químicas
Ingeniería civil, construcciones y obras publicas
Ingeniería mecánica
Metalurgia
Tecnología de los polímeros, pintura, madera
Telecomunicaciones, teoría y procesamiento de señales
Nano ciencias, nanotecnologías
Ciencias de la vida y medio ambiente
Biología, salud
Biología molecular y estructural, bioquímica
Genética, genómica, bioinformática
Biología celular, biología del desarrollo animal, zoología, ciencias veterinarias
Fisiología, fisiopatología, biología sistémica medical
Datos de libre acceso en la web (con mención de una licencia abierta);
Datos en un formato estructurado (legible por una máquina);
Formato no propietario (CSV, RDF,…);
Estándares W3C y URI para identificar cada recurso;
Datos vinculados a otros datos RDF vía alineaciones.
Esquemáticamente, los recursos terminológicos expuestos en Loterre pueden ser del tipo:
vocabularios en sentido amplio: glosarios, listas de términos, tesauros;
taxonomías (planos de clasificación y similares).
Los datos de tipo recursos léxicos, recursos de análisis de contenidos u ontologías sólo podrán ser integrados en Loterre si están convertidas en formato SKOS, lo que puede conllevar alguna pérdida de informaciones con respecto al contenido originario.
Su estructuración puede:
presentar una jerarquía simple, múltiple o no presentar ninguna jerarquía;
presentar agrupamiento (colecciones, grupos, campos o facetas).
Diseño de Loterre
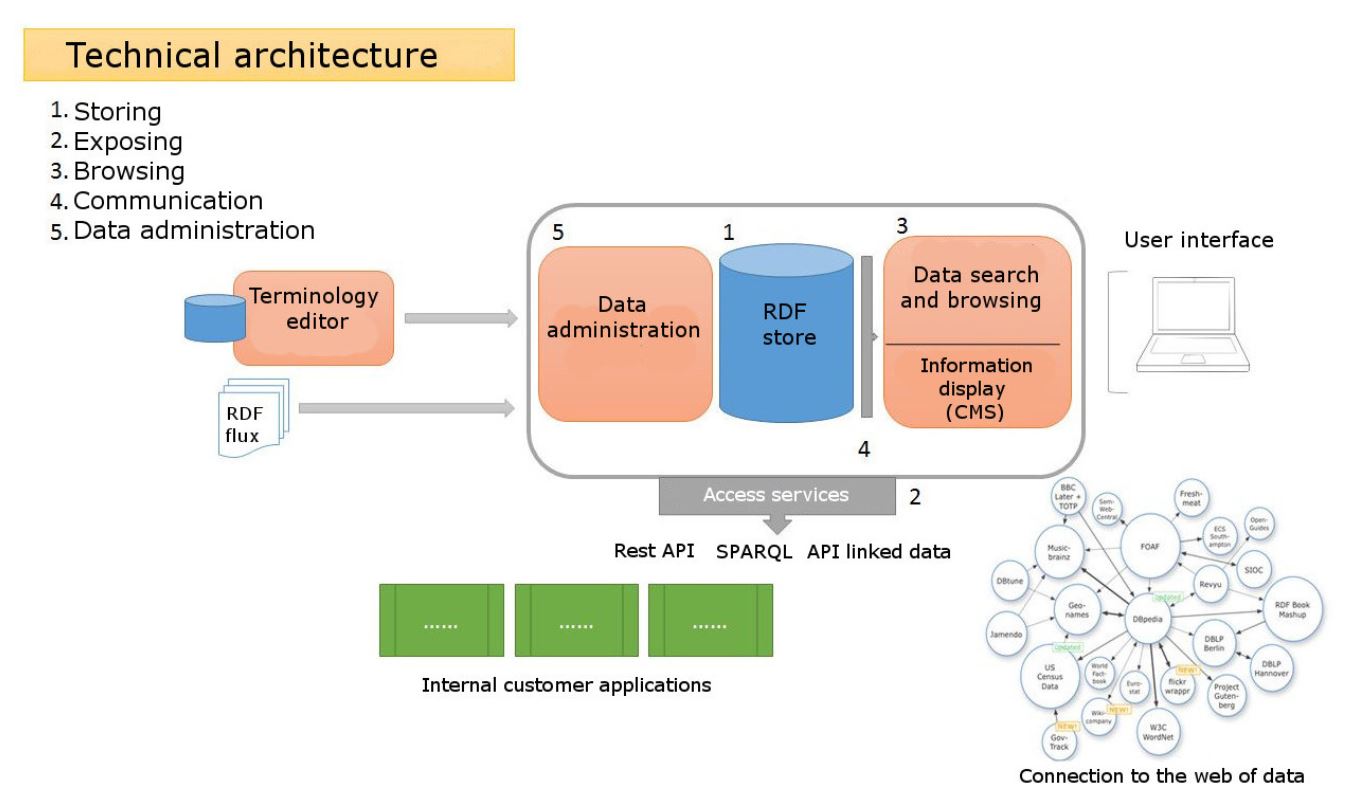
La arquitectura de Loterre se basa en un triplestore equipado con una herramienta de consulta humana y buscable a través de una interfaz SPARQL y una API.
Para ofrecer a sus utilizadores un acceso a las terminologías, Loterre recurre a diversas herramientas open-source:
¿Una de sus preguntas sigue sin respuesta? Pídalo directamente, con el formulario de contacto.
Modelo de datos
Haga clic en las preguntas a continuación para obtener más información sobre la plataforma Loterre
Las terminologías incluidas en el triplestore se expresan según un modelo de tipo «SKOS extendido», que asocia con el estándar SKOS una serie de clases y propiedades pertenecientes a otros vocabularios (lista no exhaustiva):
This property allows the linkage of two different pieces of software such that one directly executes or uses the other. The has_part relationship should instead be used to describe related but independent members of a larger software package, and 'uses platform' relationship should be used to describe which operating system(s) a particular piece of software can use.
is implemented by is the relationship between an algorithm and a piece of software which includes an implementation of that software for use when the software is executed.
Entity A is 'directly preceded by' entity B if there are no intermediate entities temporally between the two entities. WIthin SWO this property is mainly used to describe versions of entities such as software.
'directly followed by' is an object property which further specializes the parent 'followed by' property. In the assertion 'C directly followed by C1', says that Cs generally are immediately followed by C1s.
'uses platform' should be used to link a particular piece of software to one or more operating systems which that software can run on. This is in contrast to both 'uses software' (which describes one piece of software directly executing another), and has_part, which can be used to describe related but independent software in a package, for example.
Provides a method of asserting what type of interactions are possible for the class in question. The interface must be from the 'software interface' hierarchy.
is executed in defines the relationship between a software class and an appropriate process in the information processing hierarchy. Specifically, it allows the linking of a particular piece of software to a process of a particular purpose,
Axioms using the 'has clause' property, e.g. C 'has clause' C1, provide links from the left hand class to the instances within the 'license clause' hierarchy. This provides a way to more precisely assert the constraints of the licensing applied.
The relationship between an entity and the set of legal restrictions, i.e. license, which are applied in using or otherwise interacting with that entity. Eg. relationship between a software license and the software which implements it.
With both a domain and range of 'data format specification', this property provides a means of stating that two different data format specifications are valid specifications for the same type of data.
The relationship between an entity and the set of legal restrictions, i.e. license, which are applied in using or otherwise interacting with that entity. Eg. relationship between software and a software license.
'is compatible license of' provides a method of marking two software licenses as compatible and without conflicts, e.g. that the Apache License version 2 is compatible with GNU GPL version 3. If two licenses are connected with this property, it means code released under one license can be released with code from the other license in a larger program.
'has declared status' provides a way to assert the developmental status of a class, such as whether it is stable or under development. Is especially useful for software that might not be complete or stable yet, and when combined with version information.
A related resource that references, cites, or otherwise points to the described resource. [This property is intended to be used with non-literal values. This property is an inverse property of References.]
La nomenclature NUTS (Nomenclature des unités territoriales statistiques) est un système hiérarchique de découpage du territoire économique de l'UE et du Royaume Uni...
Correspond à un groupe d'entrées terminologiques (concepts). Cette classe peut être remplacée par la classe "isothes:ConceptGroup" ou par la classe "rdf:Description" en précisant le type "http://www.w3.org/2004/02/skos/core#Collection" ou "http://purl.org/iso25964/skos-thes#ConceptGroup" dans l'attribut "rdf:resource" d'une balise "rdf:type"
Correspond à une entrée terminologique. Cette classe peut être remplacée par la classe "rdf:Description" en précisant le type "http://www.w3.org/2004/02/skos/core#Concept" dans l'attribut "rdf:resource" d'une balise "rdf:type"
Correspond à un groupe d'entrées terminologiques (concepts). Cette classe peut être remplacée par la classe "skos:Collection" ou par la classe "rdf:Description" en précisant le type "http://www.w3.org/2004/02/skos/core#Collection" ou "http://purl.org/iso25964/skos-thes#ConceptGroup" dans l'attribut "rdf:resource" d'une balise "rdf:type"
Correspond à une référence bibliographique en rapport avec un concept (ou une collection de concepts). Ne pas confondre avec la propriété "dct:bibliographicCitation" utilisée au sein de cette classe.
Correspond au niveau ressource terminologique (vocabulaire) à la quelle les entrées terminologiques (concepts) sont rattachées. Cette classe peut être remplacée par la classe "rdf:Description" en précisant le type "http://www.w3.org/2004/02/skos/core#ConceptScheme" dans l'attribut "rdf:resource" d'une balise "rdf:type"
Información, herramientas o servicios útiles para publicar recursos terminológicos en la web de datos
Haga clic en los elementos a continuación para plegarlos o desplegarlos.
RDF
El Marco de Descripción de Recursos (del inglés Resource Description Framework, RDF) es una familia de especificaciones de la World Wide Web Consortium (W3C) originalmente diseñado como un modelo de datos para metadatos. Ha llegado a ser usado como un método general para la descripción conceptual o modelado de la información que se implementa en los recursos web, utilizando una variedad de notaciones de sintaxis y formatos de serialización de datos. (Fuente: Wikipedia)
SKOS
SKOS (siglas de Simple Knowledge Organization System) es una iniciativa del W3C en forma de aplicación de RDF que proporciona un modelo para representar la estructura básica y el contenido de esquemas conceptuales como listas encabezamientos de materia, taxonomías, esquemas de clasificación, tesauros y cualquier tipo de vocabulario controlado. (Fuente: Wikipedia)
OWL es el acrónimo del inglés Web Ontology Language, un lenguaje de marcado para publicar y compartir datos usando ontologías en la WWW. OWL tiene como objetivo facilitar un modelo de marcado construido sobre RDF y codificado en XML.
Tiene como antecedente DAML+OIL, en los cuales se inspiraron los creadores de OWL para crear el lenguaje. Junto al entorno RDF y otros componentes, estas herramientas hacen posible el proyecto de web semántica. (Fuente: Wikipedia)
El URI es uno de los componentes básicos de la red de datos en el sentido de que cada recurso está identificado de forma única y permanente por un URI.
La NMA (Name Adressing Authority , Autoridad de direccionamiento de nombres) es responsable de hacer que la URL sea cliqueable en un navegador web.
El identificador ARK en sí, que consta de:
de la etiqueta (esquema) «ark:/»,
un código numérico que corresponde al NAAN (Name Assigning Authority Number, Número de Autoridad de Asignación de Nombres) asignado a solicitud por la CDL a las organizaciones que producen recursos documentales.
de una cadena alfanumérica asignada a cada concepto y que termina con un carácter de control (Suma de comprobación).
Herramienta de representación de recursos en formato SKOS, que permite visualizar o imprimir diferentes aspectos de una terminología
Documentación: http://labs.sparna.fr/skos-play/?lang=fr
Herramienta para publicar juegos de datos (csv, tsv, xml, json, …) en formatos de la web semántica (JSON-LD, N-Quads, …) y manipularlos en un back-office. Desarrollado en el Inist.
Documentación: https://github.com/Inist-CNRS/lodex
Aplicación para transformar datos brutos en un gráfico de conocimiento.
OnAGUI
OnAGUI (Ontology Alignment Graphical User Interface) es una herramienta para buscar y validar los alineamientos entre conceptos de recursos terminológicos (en formatos SKOS o OWL), gracias a diferentes algoritmos.
Documentación: https://github.com/lmazuel/onagui
YAM++ Matcher
Aplicación en línea destinada a buscar y validar alineamientos entre tesauros y ontologías, desarrollada en el LIRMM
Documentación: http://yamplusplus.lirmm.fr/
OpenRefine
OpenRefine es mucho más que una herramienta de alineación; Este software gratuito permite de manera más general la limpieza y el formateo de datos de texto tabulares. Pero resulta especialmente útil en términos de alineación, una función llamada "reconciliación" en la terminología de la herramienta, porque permite conectarse a las API de muchas bases de datos, incluidas Wikipedia o Wikidata, para buscar los identificadores de conceptos equivalentes, para ser validados en su interfaz.
Documentación: https://openrefine.org/
Haga clic en los encabezados a continuación para mostrar u ocultar su contenido.
Utilice el formulario de contacto para enviarnos un mensaje. Si su mensaje se refiere a un vocabulario específico, por favor especifíquelo.
Si está considerando diseñar un nuevo recurso terminológico, le ofrecemos apoyo. Este proyecto requiere una estrecha colaboración entre los expertos de su dominio y nuestros ingenieros, quienes aportarán sus conocimientos y habilidades en ingeniería terminológica.
Este recurso puede tener varios propósitos de uso: armonizar la terminología del campo resolviendo problemas de polisemia y homonimia; promover el intercambio de conocimientos a través de un recurso en línea de libre acceso, consultable y descargable; servir como repositorio para indexar conjuntos de datos científicos en repositorios de investigación; y, por último, constituir una herramienta educativa que facilite la exploración y el intercambio de conocimientos, particularmente en el contexto de la web semántica.
Juntos, en función de sus necesidades, público objetivo y recursos disponibles, desarrollaremos una metodología paso a paso utilizando nuestras herramientas especializadas de gestión y producción como Sketch Engine, TermSuite, VocBench, OpenRefine y otras.
No existe una única manera de construir un recurso terminológico, sino que nuestro trabajo sigue un marco metodológico general que adaptamos al caso concreto.
Antes de desarrollar un recurso terminológico, se recomienda realizar un trabajo preparatorio que incluya la identificación de potenciales contribuyentes, la evaluación de los recursos existentes, la definición del alcance científico y la elección del tipo de recurso a crear (tesauro, léxico, glosario, etc.).
Una vez realizado el estudio preliminar que ha permitido definir el alcance y el tipo de recurso que se desea crear, se trata entonces de recopilar los términos pertinentes que constituirán su contenido. Este paso generalmente comienza con la creación de un corpus. A menudo partimos de una lista de términos candidatos extraídos automáticamente de este corpus textual, pero los recursos existentes, las extracciones de palabras clave de autores o los índices de obras también son fuentes de interés. El objetivo de la recopilación de términos es constituir un reservorio terminológico que sirva de base de trabajo para las etapas siguientes (curación, estructuración, enriquecimiento). Los elementos terminológicos recuperados en esta etapa van desde un simple término candidato hasta un concepto completo que ya contiene términos preferenciales, equivalentes y definiciones.
Después de recopilar los términos candidatos, es necesario un proceso de clasificación para eliminar los términos fuera de dominio, obsoletos, redundantes o no nominales, mientras que se conservan las variantes, los sinónimos y los términos que deben corregirse. Esta fase de limpieza, que requiere mucho tiempo, puede continuar durante la etapa de estructuración porque el desarrollo de la terminología es un proceso global e iterativo en lugar de una secuencia lineal. La lista final obtenida será luego completada para llenar los vacíos, para luego ser estructurada y enriqueceda.
La estructuración de conceptos permite explorar un recurso terminológico en diferentes niveles de especificidad y establecer mecanismos de herencia. Esta estructuración se basa en tres tipos principales de relaciones:
relaciones jerárquicas (genérico-específico, partitivo, instancia) que ayudan a escribir definiciones formales;
relaciones asociativas no jerárquicas entre conceptos relacionados;
relaciones de equivalencia entre variantes terminológicas.
Un cuarto tipo de relación permite la agrupación temática de conceptos por dominio. Para establecer estas estructuras se puede utilizar literatura científica, ontologías existentes o herramientas de procesamiento automático del lenguaje.
El enriquecimiento final del contenido del tesauro es un proceso continuo que incluye varias acciones: añadir definiciones (escritas o extraídas de fuentes existentes), integrar referencias bibliográficas opcionales a través de las propiedades de Dublin Core, realizar alineaciones con otros recursos (manualmente o utilizando herramientas especializadas), incorporar relaciones conceptuales más precisas y agregar datos adicionales como coordenadas geográficas o identificadores. Para un tesauro multilingüe, todos estos campos deben completarse en cada idioma.
El paso final consiste en convertir los recursos terminológicos para su publicación en Loterre en el mundo de Linked Open Data (LOD). Este proceso incluye el uso de estándares de datos web, la asignación de identificadores URI únicos y la adopción de una licencia abierta. Los archivos originales se convierten a RDF/SKOS y se verifica su conformidad con el modelo de datos.
Un ejemplo de realización: Paleosaurus
En 2020, Paleosaurus es una iniciativa del Departamento de Bibliotecas de la Universidad de París-Saclay, que reúne a expertos en información y paleoclimatólogos de varios laboratorios (LSCE, Géosciences Paris-Saclay y Montpellier). Fruto de esta colaboración, el tesauro de paleoclimatología describe y estructura por primera vez alrededor de 2000 términos y conceptos de la disciplina, en francés e inglés. Diseñado para proporcionar a la comunidad científica un vocabulario de referencia, facilita el intercambio de datos y producciones científicas en paleoclimatología en la web.
El tesauro paleoclimatológico se distingue por su estructura polijerárquica que comprende 2000 entradas conceptuales organizadas en una treintena de conceptos superiores, sus conceptos enriquecidos con sinónimos, definiciones y relaciones de asociación con otros conceptos, así como por la alineación sistemática de sus conceptos con los sistemas internacionales de organización del conocimiento.
Para crear el tesauro se compiló un corpus de casi 40.000 documentos (1890-2020) de las bases de datos WOS, Scopus e Istex. La extracción de terminología con TermSuite identificó más de 140.000 términos, reducidos a una lista de 7.000 términos. Luego, siete investigadores en paleoclimatología seleccionaron y validaron 2.000 conceptos, clasificados dentro de una treintena de los mejores. Todos estos conceptos han sido traducidos al francés y alineados con sistemas internacionales como Wikipedia. El tesauro se enriqueció con definiciones (tres cuartas partes de los conceptos tienen definiciones en francés e inglés) antes de ser estructurado y publicado en la plataforma Loterre.
Más de la mitad de los recursos publicados en Loterre proceden de socios que desean beneficiarse de este portal y sus servicios para promover su terminología.
Si ya dispone de un recurso terminológico, podemos encargarnos de las operaciones técnicas de convertirlo a SKOS, verificarlo y asignarle identificadores únicos (ARK) para su publicación en el portal Loterre.
Estos son los requisitos mínimos para que el contenido sea elegible directamente para unirse a Loterre:
el recurso debe tratar sobre un campo/tema científico,
debe aceptar la carta de Loterre que establece en particular todos los aspectos relativos a los derechos y la distribución,
Su recurso debe estar al menos en francés o inglés (ambos idealmente).
Si su recurso no es lo suficientemente rico y homogéneo, podemos colaborar para enriquecerlo y organizarlo para acercarlo a nuestros estándares.
No dude en contactarnos para hablar de su proyecto; Seguramente podremos trabajar juntos para desarrollar una solución adecuada que enriquecerá su contenido terminológico: formulario de contacto.
Compromisos de Loterre
La publicación de recursos terminológicos en Loterre es gratuita, dentro de los límites de volúmenes que estén dentro de las capacidades técnicas de la plataforma y dentro de los límites de los criterios definidos en el apartado «Selección de recursos».
Los administradores de Loterre se comprometen a hacer todo lo posible para garantizar el acceso continuo al servicio.
Metadatos
Inist produce un archivo de metadatos para cada recurso, basado en la información proporcionada por el propietario del recurso. Estos metadatos se pueden recopilar en un archivo VoID.ttl (Vocabulario de conjuntos de datos interconectados).
La lista de metadatos se puede ver en la pestaña «Modelo de datos».
Gestión de URI desreferenciables
En la mayoría de los casos, las URI que se muestran en Loterre son del tipo:
http://data.loterre.fr/CódigoDeProductor/CódigoDeRecurso para un recurso
http://data.loterre.fr/CódigoDeProductor/CódigoDeRecurso/IdentificadorDeConcepto para un concepto de este recurso
Con:
CódigoDeProductor: un código para identificar la organización que creó el recurso.
CódigoDeRecurso: código utilizado para identificar el recurso
IdentificadorDeConcepto: identificador de un concepto en el recurso
Si el productor tiene una cuenta que le permite registrar un DOI para su recurso, este elemento puede registrarse en los metadatos de su recurso en Loterre.
Gestión de versiones
Si se actualiza un recurso, la versión guardada en el almacén triple y disponible para descargar es la más reciente.
Se pueden proporcionar archivos descargables para versiones anteriores a pedido.
Gestión de archivos de usuario
Loterre ofrece servicios que permiten a los usuarios convertir, controlar y enriquecer sus propios datos. Ver menú «Servicios».
Los datos de usuario tratados por estos servicios solo se utilizarán durante la duración de una sesión y no serán conservados por Inist-CNRS.
Compromisos de los colaboradores
Para depositar un recurso en Loterre es necesario que el colaborador cuente con plena autorización para depositar por parte del propietario o beneficiario legal del recurso y tenga conocimiento exacto de sus derechos de uso.
Por tanto, el colaborador deberá:
estar autorizado a tomar cualquier decisión relativa al uso y difusión del recurso (propiedad intelectual en particular);
poder proporcionar toda la información relacionada con las fuentes del recurso.
Para ser publicados en Loterre, lo ideal es que los recursos se proporcionen como archivos SKOS/RDF.
Sin embargo, si el colaborador no puede proporcionar datos en este formato, Inist puede realizar el trabajo de conversión/verificación necesario basándose en los datos proporcionados por el colaborador. Asimismo, Inist podrá encargarse de la creación de los archivos PDF o CSV ofrecidos para su descarga.
Nota: un servicio (menú «Servicios» / pestaña «Transformar») está disponible en Loterre para permitir a los usuarios realizar transformaciones ellos mismos desde un formato de hoja de cálculo como CSV a SKOS o de SKOS a CSV, HTML o PDF.
Licencia
Al momento de enviar el trabajo, el colaborador deberá especificar la naturaleza de la licencia adjunta al recurso. Esta licencia debe autorizar el suministro y reutilización de datos, con vistas a la «Ciencia Abierta».
Ejemplos de licencias abiertas aplicables a este tipo de datos: